Automatic Docker volume backups on Backblaze B2 with Terraform
Creating an automatic backup strategy for Docker volumes, on Backblaze B2 buckets managed with Terraform, with state files securely saved on B2 as well.
On different machines I’ve been running a number of Docker containers, some of which have volumes that I’m interested in backing up (and restoring, in case bad things happen).
I’ve been using offen/docker-volume-backup for quite some time, which is a great project that allows to automatically backup Docker volumes to multiple places, including local filesystems, WebDAV, SSH remotes, S3, Dropbox.
The problem is that I didn’t really have a backup strategy, meaning that the only cool thing in my setup was this offen/docker-volume-backup thingy, which I configured to just backup locally; then periodically I used to manually copy backup tars somewhere else for long-term storage. Backups were also not encrypted.
That approach is okaysh if you just want to have backups, but:
- It feels like a chore.
- Lacks standardization.
- May go wrong for human error.
- It is a waste of time.
- It is simply not good enough.
The solution
From the problems just stated, directly follows the solution I adopted, which goal is to:
- Automate the long-term storage of backups.
- Use a secure storage.
- Use Infrastructure-as-Code (IaC) to define the storage properties.
On a high-level view, I ended up making this:
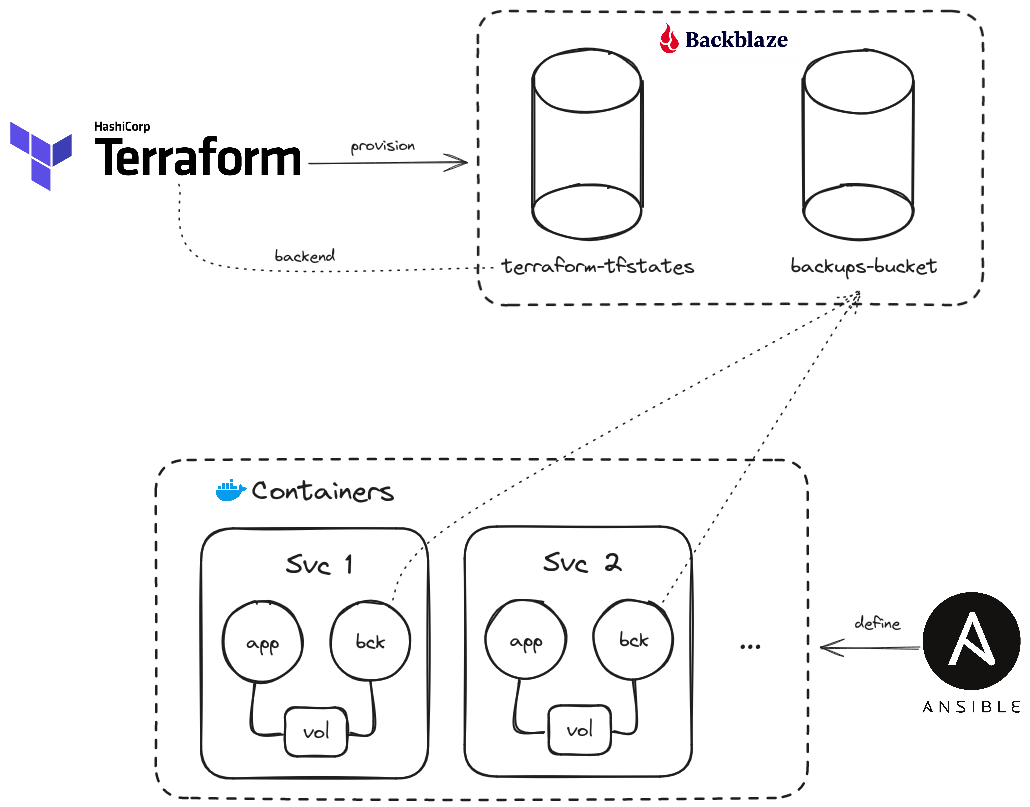
I’m using:
offen/docker-volume-backupto:- Backup Docker volumes.
- Encrypt them with PGP.
- Push them to a Backblaze B2 bucket.
- Manage its own retention policy.
- Two Backblaze B2 buckets to:
- Store backups.
- Store the Terraform statefiles.
- Two Terraform modules to describe the B2 buckets.
Let’s see all.
Backblaze application keys
Before even starting, we want to have a proper access management, meaning that we need two different sets of privileges:
- A broad set for Terraform.
- A restricted set for docker-volume-backups operations.
To achieve this, we can create two application keys on Backblaze. Let’s respectively call them $K_t$ and $K_o$. We need to annotate the their keyID and keyName.
Terraform
We’ll have two Terraform modules:
backblaze-tfstates: to manage Terraform state files storage.backups-bucket: to manage the backups storage.
The structure is:
.
├── backblaze-tfstates
│ ├── backend.tf
│ ├── main.tf
│ ├── outputs.tf
│ ├── requirements.tf
│ └── variables.tf
└── backups-bucket
├── backend.tf
├── main.tf
├── outputs.tf
├── requirements.tf
└── variables.tf
backblaze-tfstates
Since state files can contain secrets, we want to store them in a secure location; we’ll use this bucket for it. Let’s define it.
Here we are going to use the $K_t$ application key (and ID) that we saw before.
main.tf
provider "b2" {
application_key = var.application_key
application_key_id = var.application_key_id
}
resource "b2_bucket" "tfstates" {
bucket_name = "tfstates-${random_string.suffix.id}"
bucket_type = "allPrivate"
default_server_side_encryption {
algorithm = "AES256"
mode = "SSE-B2"
}
}
resource "random_string" "suffix" {
lower = true
upper = false
special = false
length = 10
}
Some observations:
- Application keys are given, not hardcoded.
- Since B2 bucket names have a global scope, we are adding a random suffix.
variables.tf
variable "application_key" {
type = string
sensitive = true
}
variable "application_key_id" {
type = string
sensitive = true
}
The only observation is that our inputs are marked as sensitive, to mask them in Terraform plan/apply/destroy.
outputs.tf
output "bucket_name" {
value = b2_bucket.tfstates.bucket_name
}
requirements.tf
terraform {
required_version = ">= 1.0.0"
required_providers {
b2 = {
source = "Backblaze/b2"
}
}
}
backend.tf
This file will contain the configuration of the Terraform backend to use. Since the bucket where we are going to store our states is exactly this one, we’ll keep this file empty for the moment, and populate it only after our bucket is created.
Now we are free to terraform plan and terraform apply, after which we will have:
- A new bucket; let’s say it is called
tfstates-abc123cde0. - A statefile in the local directory, called
terraform.tfstate.
Now we want to change the backend configuration to tell Terraform to use the newly created bucket as backend. Here is how we can do it:
terraform {
backend "s3" {
bucket = "tfstates-abc123cde0"
key = "backblaze-tfstates.tfstate"
region = "eu-central-003"
endpoints = {
s3 = "https://s3.eu-central-003.backblazeb2.com"
}
skip_s3_checksum = true
skip_credentials_validation = true
skip_region_validation = true
skip_metadata_api_check = true
skip_requesting_account_id = true
}
}
Some observations:
- We are using the Amazon S3 backend because Backblaze B2’s API is compatible with S3.
- The
skip_xparameters are necessary to work with B2.
At this point, we can perform a terraform init -migrate-state to easily tell Terraform to use the new backend and to push the state to our nice bucket.
It is also possible to manually push the state to the new backend, instead of letting Terraform automatically migrate it.
The way to do it is:
- Delete the
.terraform/terraform.tfstatefile. - Execute
terraform init. - Execute
terraform state push local-state-name.tfstate.
backups-bucket
main.tf
Similarly, we are giving the same keys, then creating a bucket with a random suffix.
provider "b2" {
application_key = var.application_key
application_key_id = var.application_key_id
}
resource "b2_bucket" "backups" {
bucket_name = "backups-bucket-${random_string.suffix.id}"
bucket_type = "allPrivate"
}
resource "random_string" "suffix" {
lower = true
upper = false
special = false
length = 10
}
output.tf
output "bucket_name" {
value = b2_bucket.backups.bucket_name
}
The other files (backend.tf, requirements.tf, variables.tf) contain the same configuration seen before.
At this point, after terraform plan and terraform apply we will have everything we need at infrastructure level.
Automated backups
Now we want to automatically perform encrypted backups and push them to our backups bucket.
Just to set some context, let’s take a real-life example and say that we have a docker-compose file like this:
version: "2"
services:
baikal:
image: ckulka/baikal:0.9.3-nginx
volumes:
- ./config/:/var/www/baikal/config
- data:/var/www/baikal/Specific
restart: always
backup:
image: offen/docker-volume-backup:v2.34.0
env_file:
- .env_backup
volumes:
- /var/run/docker.sock:/var/run/docker.sock:ro
- data:/backup/baikal:ro
- ./backups:/archive
restart: always
volumes:
data:
networks:
default:
external:
name: proxy
Specifically, we have:
- A service (baikal in this example) that contains some data that we want to backup.
- This data is in a Docker volume called
data. - We have
docker-volume-backupthat uses thedatavolume. docker-volume-backupreads its configuration from.env_backup.
.env_backup
Our backup configuration may look like:
BACKUP_CRON_EXPRESSION=0 3 * * *
BACKUP_FILENAME=backup-%Y-%m-%dT%H-%M-%S.tar.gz
BACKUP_LATEST_SYMLINK=backup.latest.tar.gz
BACKUP_EXCLUDE_REGEXP=\.log$$
BACKUP_ARCHIVE=/archive
BACKUP_RETENTION_DAYS=30
BACKUP_PRUNING_PREFIX=backup-
BACKUP_PRUNING_LEEWAY=1m
BACKUP_STOP_CONTAINER_LABEL=baikal
GPG_PASSPHRASE={{ backups.gpg_passphrase }}
AWS_S3_BUCKET_NAME={{ backups.bucket_name }}
AWS_S3_PATH=baikal
AWS_ENDPOINT={{ backups.endpoint }}
AWS_ACCESS_KEY_ID={{ backups.access_key_id }}
AWS_SECRET_ACCESS_KEY={{ backups.secret_access_key }}
Some words:
- The
BACKUP_*section is about defining frequency, naming, retention policies, whether to stop contains before backing up, etc. - The presence of
GPG_PASSPHRASEis sufficient to tell the system to encrypt files with the given passphrase. - In the
AWS_*section we are using the backups bucket, and pushing encrypted backups in the service name directory (baikalin this case). - Here we have the Jinja2 syntax
{{ something }}just because I’m also using Ansible and storing these values withansible-vault, but it’s not in the scope of this post. - We must manually track updates to our GPG passphrase.
Another important thing to say is that here we are are using the $K_o$ application key (and ID).
Conclusion
At this point, our automated backup strategy is ready to operate. To summarize, now we have:
- A bucket to store encrypted backups.
- A bucket to store Terraform’s statefiles.
- A IaC definition of our buckets.
- A backup container that periodically:
- Creates backups.
- Encrypts them with a GPG passphrase.
- Uploads them to our B2 bucket.
Thanks for the read, bye 👋